 诶妈呀!这不是一直需要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下方法。
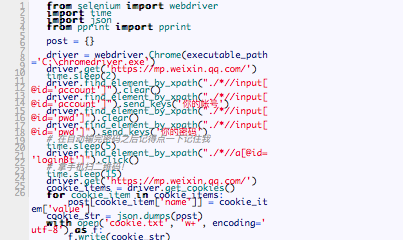
2、其次你需要登录!
这个暂且不说了,我使用的是selenium 驱动浏览器获取Cookie的方法,来达到登录的效果。
3、使用requests携带Cookie、登录获取URL的token(这玩意儿很重要每一次请求都需要带上它)像下面这样:
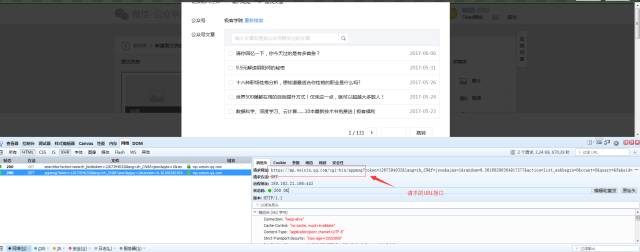
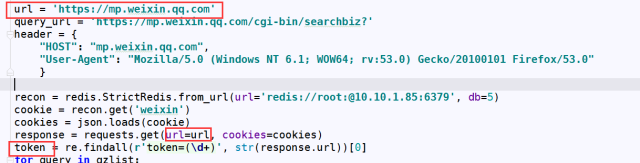 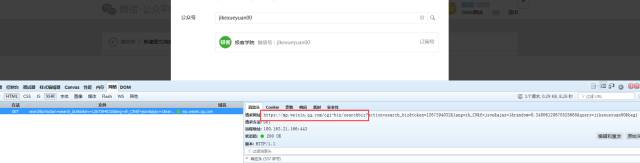 我们在搜索公众号的时候浏览器带着参数以GET方法想红框中的URL发起了请求。请求参数如下:
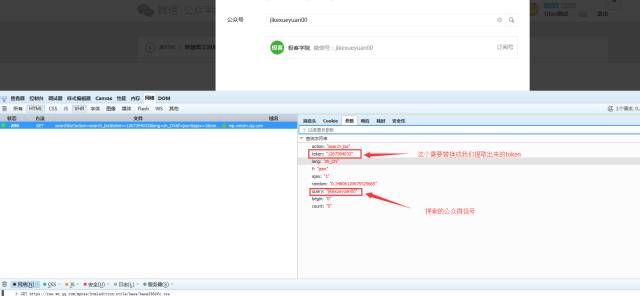
请求相应如下:
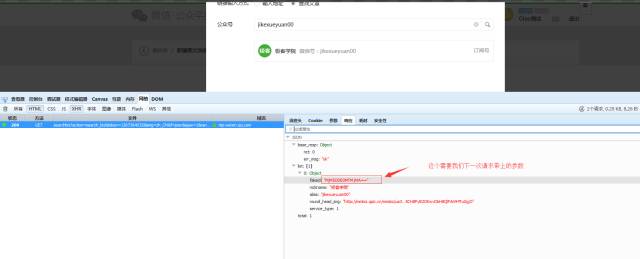 代码如下:
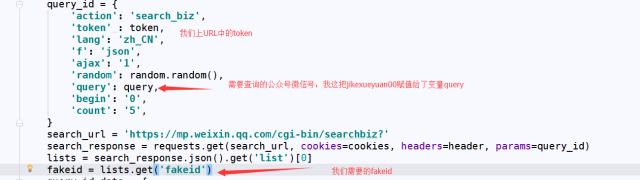 好了 我们再继续:
 请求参数如下:
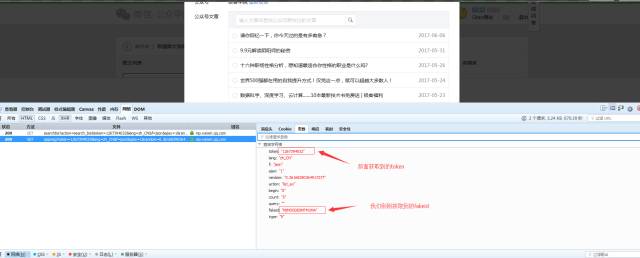 返回如下:
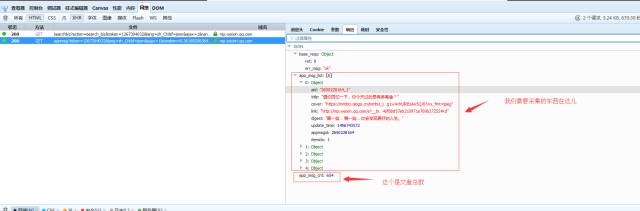 代码如下:
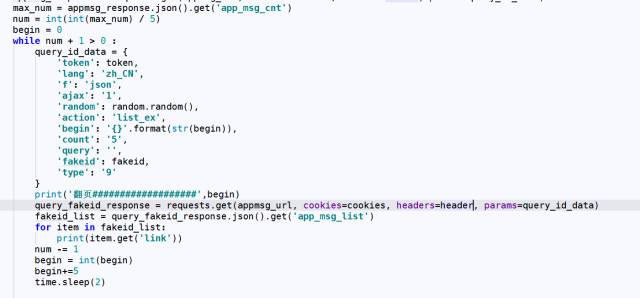
 好了···最后一步,获取所有文章需要处理一下翻页。翻页请求如下:
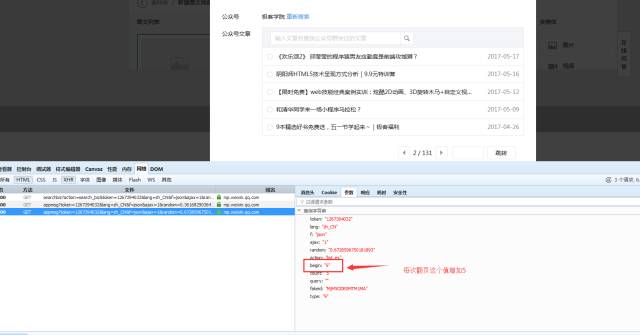 我大概看了一下,极客学院每一页大概至少有5条信息,也就是总文章数/5 就是有多少页。但是有小数,我们取整,然后加1就是总页数了。
代码如下:
|